一、前言
在电赛信号题的实践中,我们经常碰到类似需要高速ADC/DAC的情况,在STM32内置的ADC/DAC精度或者分辨率无法达到需求的时候,我们往往需要采用外部ADC/DAC芯片+FPGA来实现信号采集/重建。在考虑这套方案时绕不开的一个话题便是FPGA与单片机的高速通讯。我们需要一个稳健性强且速度高的方案来实现海量数据的传输。考虑到上述需求我们采用基于SPI通信协议的单片机与FPGA通信方案。单片机方面我们开启DMA数据传输来进一步提高传输效率。经测试该方案能完美达成电赛场景下海量数据传输的需求,在日常开发中也具有一定参考价值与意义。
(事实上使用uart也完全可以达成相同的目的。但是我们队伍最开始考虑到ADC/DAC数据位数可能大于8位,故选择了spi方案。当然事实上使用字节拼接的方式完全可以解决这个问题,但后面方案已经定下来代码都写差不多了也就懒得改了,差不多得了罢)
二、SPI通信协议浅析
SPI,是英语Serial Peripheral interface的缩写,顾名思义就是串行外围设备接口。是Motorola首先在其MC68HCXX系列处理器上定义的。SPI接口主要应用在 EEPROM,FLASH,实时时钟,AD转换器,还有数字信号处理器和数字信号解码器之间。SPI,是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便,正是出于这种简单易用的特性
2.1 SPI主从控制方式
SPI 规定了两个 SPI 设备之间通信必须由主设备 (Master) 来控制次设备 (Slave)。 一个 Master 设备可以通过提供 Clock 以及对 Slave 设备进行片选 (Slave Select) 来控制多个 Slave 设备,SPI 协议还规定 Slave 设备的 Clock 由 Master 设备通过 SCK 管脚提供给 Slave 设备, Slave 设备本身不能产生或控制 Clock,没有 Clock 则 Slave 设备不能正常工作。
2.2 SPI协议接线
SPI总线由四根线构成:
- SDO/MOSI: 主设备数据输出,从设备数据输入
- SDI/MISO: 主设备数据输入,从设备数据输出
- SCK: 时钟信号,由主设备产生
- CS/SS: 片选信号,从设备使能,一般来说在存在多设备构成的总线结构中起到设备使能的作用。另一方面在高速通信的情况下通过在非使用期间CS引脚拉高可以降低干扰,提高传输稳健性

2.3 SPI传输流程
2.3.1 关于数据交换
SPI通信协议不同于传统通信协议,其设备间的数据传输被称为数据交换。具体来说在每个时钟周期内,无论是主设备还是从设备,都会发送并且接收一个bit大小的数据。也就是说,SPI并无读与写的说法,任何设备无论主从发一个数据必然会收到一个数据,要收一个数据必须也要先发一个数据。
2.3.2 极性与相位
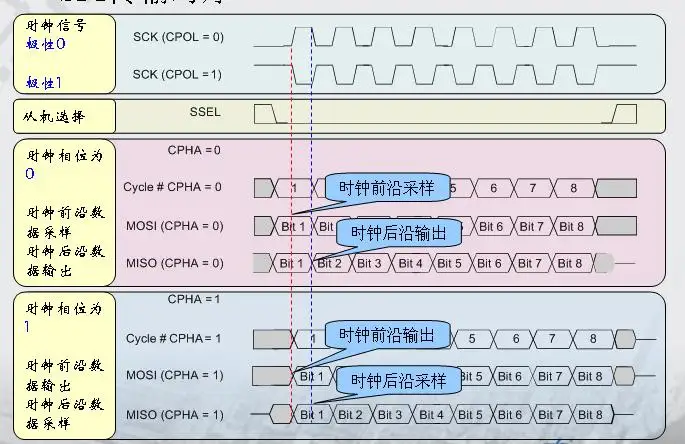
SPI总线有两个主要参数:CPOL与CPHA。他们分别决定了SPI数据传输发送与读取是发生在时钟的上升沿还是下降沿,SPI总线空闲时是高电平还是低电平。
 CPHA代表相位。当CPHA=1时,读取数据发生在下降沿,数据的改变发生在上升沿。CPOL代表极性,如果CPOL=0,则先出现上升沿,再出现下降沿;如果CPOL=1,先出现下降沿,再出现上升沿。对于任一通信设备,需要提前约定好SPI的极性与相位,两者必须相匹配,不然会出现数据传输的延迟或者超前,进而导致数据读取紊乱
CPHA代表相位。当CPHA=1时,读取数据发生在下降沿,数据的改变发生在上升沿。CPOL代表极性,如果CPOL=0,则先出现上升沿,再出现下降沿;如果CPOL=1,先出现下降沿,再出现上升沿。对于任一通信设备,需要提前约定好SPI的极性与相位,两者必须相匹配,不然会出现数据传输的延迟或者超前,进而导致数据读取紊乱
2.3.3 传输流程
在传输开始时,由主设备控制CS线电平拉低,从设备检测CS线电平,得到通知则开启通信。主设备SCK线开始传输时钟信号,双方设备根据事先约定的通信规则在时钟的边沿处发送数据并接收数据。每个时钟周期发送/接收1bit,接收数据将被存放入接收设备的移位寄存器中,并循环往复
三、FPGA从STM32主的SPI通信实现
在电赛应用场景下,我们希望FPGA充当一个外设的作用。故我们选择让FPGA作为从设备,STM32作为主设备进行通信。由STM32决定何时需要数据,或者传输什么指令,将FPGA作为一个外设使用。3.1 FPGA发送实现
以下是以fpga发stm32收为例的通信实现,具体代码实现参考了https://www.cnblogs.com/cnlntr/p/14385825.html。首先是```spi_slave```模块的编写,该模块输入信号:
- clk: 时钟信号
- rst_n: 复位信号
- data_in: 待发送的数据
- spi_sck: spi时钟线
- spi_mosi: mosi线
- spi_miso: miso线
- spi_cs: 片选信号
- tx_en: 发送使能
- tx_done: 发送完成
由于cs信号为异步信号,首先我们需要同步cs信号,具体实现如下:
always @(posedge clk or negedge rst_n)begin if(!rst_n) cs_sync <= 2'b11; else cs_sync <= {cs_sync[0],spi_cs};endassign cs_nedge = cs_sync[1:0] == 2'b10;在上述代码中,异步信号cs被同步到fpga本机时钟域下。同理对sck信号也需要同步处理
always @(posedge clk or negedge rst_n)begin if(!rst_n) //SCK时钟空闲状态位高电平,工作模式3 sck_sync <= 2'b11; else sck_sync <= {sck_sync[0],spi_sck};endassign sck_nedge = sck_sync[1:0] == 2'b10;assign sck_pedge = sck_sync[1:0] == 2'b01;接下来便是发送逻辑的编写。我们选择CPOL = 1, CPHA = 2的模式,这样对于FPGA来说应该在spi时钟下降沿输出数据,对于STM32应该在spi时钟上升沿接收数据。具体过程参考2.3.3。
首先创建发送位数寄存器,控制在合适时机发送对应位数数据。寄存器在spi时钟下降沿加一,当到达发送位数最大值时归零
always @(posedge clk or negedge rst_n)begin if(!rst_n) cnt_txbit <= 0; else if (cs_nedge) cnt_txbit <= 0; else if (add_cnt_txbit) begin if(cnt_txbit == CNT_N - 1) cnt_txbit <= 0; else cnt_txbit <= cnt_txbit + 1'b1; end else if (cs_sync[1] == 1) cnt_txbit <= 0;
end
assign add_cnt_txbit = sck_nedge && tx_flag && cs_sync[1] == 0;assign end_cnt_txbit = add_cnt_txbit && cnt_txbit == CNT_N - 1;为了确保数据安全,防止数据抖动,在cs信号下降沿时,寄存器归零。
最后根据计数器的值对应位数的数据
always @(posedge clk or negedge rst_n)begin if(!rst_n) spi_miso <= 0; else if(cs_sync[1] == 0 && tx_flag) spi_miso <= data_in[CNT_N - 1 - cnt_txbit]; else spi_miso <= 0;end在完成发送时将发送完成标志置一
always @(posedge clk or negedge rst_n)begin if(!rst_n) tx_done <= 0; else if(end_cnt_txbit) tx_done <= 1; else tx_done <= 0;end完成了底层发送模块,之后便是顶层模块的编写。这里以ADC采集数据为例,首先需要将12位ADC采集数据拓展成16位,b方便发送。将ADC采集到的数据存入寄存器
input [12:0] ADC_IO,reg [15:0] ADC_data_reg;wire [15:0] ADC_data;assign ADC_data = {4'b0000,ADC_IO[11:0]};always @ (posedge sys_clk or negedge rst_n) begin if (!rst_n) ADC_data_reg <= 16'd0; else ADC_data_reg <= ADC_data;end在本例中由于要实现高速通信,SPI时钟高。为了能够正确采样SPI时钟信号,不会出现混叠现象,供给SPI底层模块的时钟信号选用PLL产生的200mHz信号。在这里顶层模块与底层模块时钟域不同,需要同步时钟域。
always @(posedge clk_200m or negedge rst_n)begin if (!rst_n) tx_done_reg <= 1'b0; //rx_done_reg <= 1'b0; else tx_done_reg <= tx_done; //rx_done_reg <= rx_done;endalways @(posedge sys_clk or negedge rst_n)begin if(!rst_n) cs_sync <= 2'b11; else cs_sync <= {cs_sync[0],I_spi_cs};endassign cs_nedge = cs_sync[1:0] == 2'b10;在这里我们捕获了发送完成信号。我们使用单端口ram作为数据缓存,先一次性存完1024个采样点,再统一通过spi发送至单片机做处理。
always @(posedge sys_clk or negedge rst_n) begin if (!rst_n) begin wr_en_flag <= 1'b0; rd_en_flag <= 1'b0; end else if (cs_nedge) begin wr_en_flag <= 1'b1; rd_en_flag <= 1'b0; end else if (wr_addr == 10'd1023) begin wr_en_flag <= 1'b0; rd_en_flag <= 1'b1; end else if (rd_addr == 10'd1023) begin wr_en_flag <= wr_en_flag; rd_en_flag <= 1'b0; end else begin wr_en_flag <= wr_en_flag; rd_en_flag <= rd_en_flag; endendassign ram_addr = wr_en_flag ? wr_addr : rd_addr此处wr_en_flag与rd_en_flag分别为单端口ram写入与读出标志。wr_addr与rd_addr为ram写入/读取地址由于stm32端采用的是软cs方案,需要在dma中断中手动拉高cs电平来表示一次传输的结束,且一次传输共接受1024个点。故我们选取cs信号下降沿作为ram写入标志,代表开启新一轮采样。当wr_addr地址到达1023时,代表采样完成,开始spi传输流程,rd_en_flag标志置1,当rd_en_flag地址到达1023时,标志一次传输完成。通过组合逻辑根据wr_en_flag切换单端口ram内存地址来源
ram_1port u_ram_1port ( .address (ram_addr), .clock (sys_clk), .data (ADC_data_reg), .rden (rd_en_flag), .wren (wr_en_flag), .q (spi_data));将ram写使能与读写能接到wr_en_flag与rd_en_flag上,将ram输出接到spi_data上。由此便完成了整个FPGA代码编写。
3.2 STM32 DMA接收实现
首先需要在cubemx中配置spi
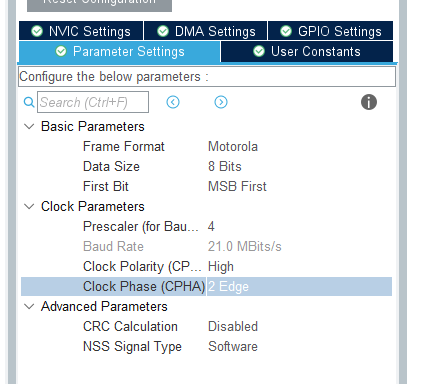
基础参数填写参照如下,并开启DMA。SPI1_RX与SPI1_TX均要开启,否则会出错
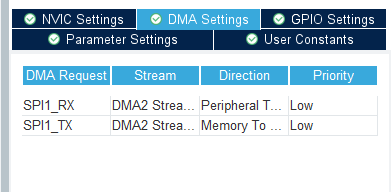
分配单独一个GPIO口作为软cs使用。SCK的GPIO需要设置成默认拉高,以提高传输稳定性。
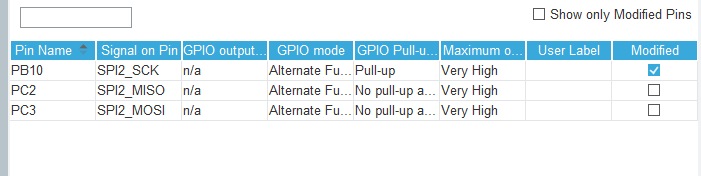
最后是代码编写,由于选择16位传输会出现错误,故我们选择8位数据传输拼接成16位数据。
#define DATAWIDTH uint16_t#define REGWIDTH uint8_t#define DATALENGTH 1024uint16_t rx_buff_16[DATALENGTH] = {0};uint8_t rx_buff[2*DATALENGTH] = {0};int main(void){ /* USER CODE BEGIN 1 */ HAL_NVIC_SetPriority(SysTick_IRQn,0,0); /* USER CODE END 1 */
/* MCU Configuration--------------------------------------------------------*/
/* Reset of all peripherals, Initializes the Flash interface and the Systick. */ HAL_Init();
/* USER CODE BEGIN Init */
/* USER CODE END Init */
/* Configure the system clock */ SystemClock_Config();
/* USER CODE BEGIN SysInit */
/* USER CODE END SysInit */
/* Initialize all configured peripherals */ MX_GPIO_Init(); MX_DMA_Init(); MX_SPI1_Init(); MX_SPI2_Init(); /* USER CODE BEGIN 2 */ HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_SET);// set cs pin to 1 when booting up //HAL_Delay(100); HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_RESET); //HAL_Delay(10); HAL_SPI_Receive_DMA(&hspi1, (uint8_t*) rx_buff, 2048); /* USER CODE END 2 */
/* Infinite loop */ /* USER CODE BEGIN WHILE */ while (1) {
/* USER CODE END WHILE */
/* USER CODE BEGIN 3 */ } /* USER CODE END 3 */}void HAL_SPI_RxCpltCallback(SPI_HandleTypeDef *hspi){
HAL_SPI_DMAStop(&hspi1); HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_SET); for (int i = 0; i < DATALENGTH; i++) { rx_buff_16[i] = (uint16_t) rx_buff[2*i+1] | (uint16_t) rx_buff[2*i]<< 8 ; } HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_SET); for (int i = 0; i < 2000; i++); HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_RESET); //for (int i = 0; i < 2000; i++);
//for (int i = 0; i < 2000; i++); //HAL_GPIO_WritePin(GPIOA, GPIO_PIN_4, GPIO_PIN_RESET); //HAL_Delay(10); HAL_SPI_Receive_DMA(&hspi1,rx_buff,2*DATALENGTH); //HAL_SPI_Receive_DMA(&hspi1,rx_buff,2*DATALENGTH);
}代码开源在了github,连接:https://github.com/sdyzjx/fpga-stm32-spi
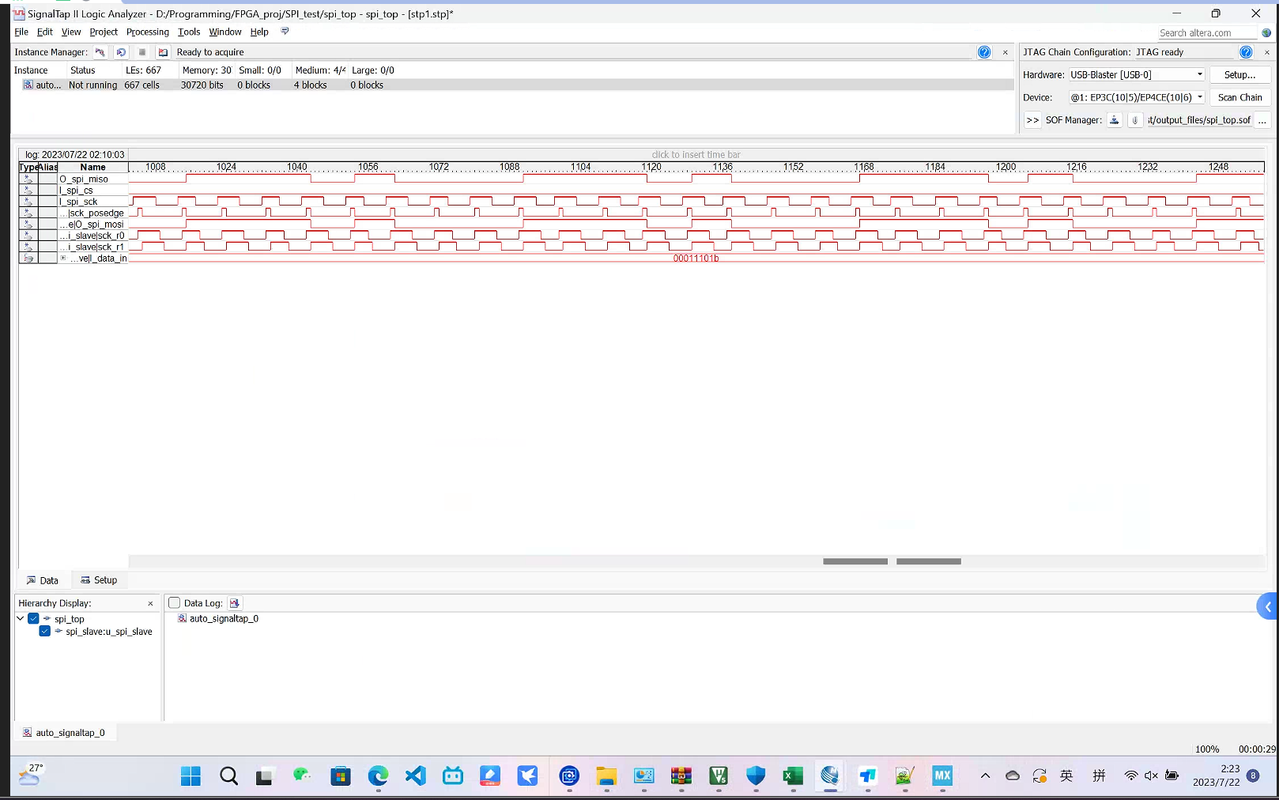
三、运行结果
模块通过了modlesims验证,并成功部署到了ep4ce10f17c8 FPGA芯片上。运行波形图如下所示: